
Autors: Marina Matafonova
Cilvēkam, skatoties uz pirkuma čeku, pietiek ar dažām sekundēm, lai saprastu, kas par preci vai pakalpojumu tika nopirkts, no kāda uzņēmuma, kad, un kāda bija kopējā summa. Bet ja gribam iemācīt to pašu datoram? IT nozares studentam Viktoram tas prasīja vairākus mēnešus. Viktora bakalaura darbs atspoguļo, cik daudz darba tiek ieguldīts šķietami vienkāršās aplikācijās. Tajās, kuras mēs lejuplādējam bez maksas, un tad vēl daži no mums raksta skarbus komentārus izstrādātājiem.
Viktors Sokolovs radīja sistēmu, kura veic personisko izdevumu uzskaiti izmantojot optisko rakstzīmju atpazīšanu (optical character recognition OCR). No lietotāja skatupunkta tā sastāv no mobilās aplikācijas, ar kuras palīdzību var nofotografēt pirkuma čeku, un web-aplikācijas, kurā var redzēt apkopotu informāciju par saviem tēriņiem. Sistēma no čeka var iegūt pārdevēja nosaukumu, pirkuma kopējo summu, pirkuma datumu, un tad ievietot datus par šiem izdevumiem attiecīgās kategorijās.
Atzītais darbs
Šo projektu Viktors ir aprakstījis un aizstāvējis, iegūstot bakalaura grādu Transporta un sakaru institūtā (TSI). Darbu atzinīgi novērtēja ne tikai augstskolas eksaminācijas komisija, bet arī “ZIBIT 2020” konkursa žūrija – Viktora Sokolova darbs izpelnījās godalgotu vietu, un pats jaunietis, kā arī darba zinātniskā vadītāja, TSI asociētā profesore Irina Pticina, saņēma īpašas stipendijas. Konkursu “ZIBIT” organizē “RTU Attīstības fonds” sadarbībā ar “Accenture” Latvijas filiāli un SIA “TietoEVRY in Latvia”. Konkursā tiek apbalvoti seši labākie IT nozares studiju noslēguma darbu autori un darbu vadītāji. “”ZIBIT” konkurss ir pērļu zvejnieks,” saka nodibinājuma “RTU Attīstības fonds” izpilddirektore Anita Straujuma, “šajā daudzu zinātnisko darbu jūrā jāatrod izcilākie jaunieši, kuri ne tikai ir aizrāvušies ar tēmu, bet ir arī drosmīgi par to pastāstīt.”
Lūk, viena no pērlēm izrādījās Viktora darbs “System Development For An Accounting Of Personal Expenses Using Optical Character Recognition”.Viktors stāsta, kā radās ideja tieši tādam projektam: “Vēlējos rakstīt bakalaura darbu izmantojot datorredzes tehnoloģijas, lai gan man nebija iepriekšējas pieredzes darbā ar tām. Sākotnēji profesore Pticina piedāvāja izveidot aplikāciju, kura no pirkuma čekiem reģistrētu informāciju par iegādes datumu, un pēc tam informētu lietotāju par to, kad precei beidzas garantija. Es sāku pētīt pieejamās iespējas, bet starpposma rezultāts bija pārāk nekvalitatīvs, tostarp dēļ tā, ka bija grūti atpazīt datus no čekiem latviešu valodā. Tad radās ideja uzlabot OCR tehnoloģijas iespējas tieši latviešu valodai. Bija ideja fotografēt čekus no pārtikas veikaliem, iegūt no tiem visu ar produktiem saistīto informāciju, un tad kādā veidā analizēt to izmantojot mašīnmācīšanos. Testi parādīja, ka programma pārāk bieži pieļauj kļūdas, atpazīstot produktu nosaukumus. Sapratu, ka vajadzēs pārāk ilgu laiku, lai sistēmu apmācītu, jo vēlējos sasniegt labu darba kvalitāti. Beigās nolēmu veidot projektu izdevumu uzskaitei, jo tad no čekiem ir jāiegūst mazāks datu apjoms, kā arī datus ir vieglāk iegūt – piemēram, kopējā pirkuma summa uz čeka parasti ir kādā veidā izcelta”.
Kā tas strādā?
Skan vienkārši, bet kādi mehānismi ir sistēmai iekšā? Tātad, ar mobilo aplikāciju lietotājs fotografē pirkuma čeku, un tālāk bilde tiek nodota serverim, kur tiek apstrādāta. Attēlam noņem fonu, gaismas atspīdumus un pēc iespējas arī visu pārējo grafisko “troksni”, paliek tikai melni simboli uz balta fona. Sagatavots attēls tālāk tiek nodots OCR-bibliotēkai, kura veic teksta atpazīšanu. Rezultātā sistēma iegūst nestrukturētu tekstu, no kura mēģina izdalīt vajadzīgos datus. Piemēram, meklējot vārdu vai vārdus pēc burtiem “SIA” vai “AS”, var uzzināt kompānijas nosaukumu un pēc tam noteikt preces vai pakalpojuma tipu. Pirkuma kopējo summu, savukārt, meklē pēc atslēgas vārdiem “Kopā”, “Summa” utt. Datumu atrast ir vieglāk, jo tas tiek meklēts pēc noteikta formāta. Ja uzņēmuma nosaukums tiek atpazīts pareizi, sistēma var atrast tā darbības jomu un attiecīgi arī noteikt, pie kādas izdevumu pozīcijas šie tēriņi ir pieskaitāmi. Lai izpildītu šo uzdevumu, sistēma pati, fona režīmā, atrod informāciju Interneta vietnē 1188.lv. Piemēram, pārdevēja nosaukums izrādījās SIA “Maxima Latvija”, uzziņu portālā atrodams, ka uzņēmuma nozare ir “Pārtikas tirdzniecība”, tātad tēriņus var pieskaitīt pie kategorijas “Pārtika”.
Tiesa, visus datus ik reizi atpazīt ar 100% precizitāti neizdodas. “Programma var sajaukt dažus burtus. Bieži jauc “o” un “u”, jo otrajam burtam augšā ir pavisam neliels attālums starp līnijām. Cilvēks var saprast starpību, bet dators ne vienmēr”, Viktors min piemēru. Viens no iemesliem ir tas, ka kases čekiem drukas kvalitāte bieži vien ir ne pārāk laba, pie tam burti un cipari diezgan ātri var izbalēt. Jāņem vērā arī tas, ka pat glabājot makā, čeks tomēr var izrādīties mazliet saburzīts tai brīdi, kad to fotografēs. Jo vairāk papīram būs defektu, jo grūtāk sistēmai strādāt ar čeku.
Tad vēl ir liels jautājums ar fontiem. “Ir grūti nosaukt vidējo radītāju veiksmīgai atpazīšanai, jo tas ir ļoti atkarīgs no čekā izmantotā fonta. Dažādu veikalu izvēlētie fonti var stipri atšķirties”, skaidro projekta autors. Cilvēkam nav lielas starpības, kādā fontā ir informācija (ja tikai tas nav pavisam eksotisks), bet datoram gan ir jāpielāgojas pie katra fonta atsevišķi. Viktors saka, ka ideālā situācijā būtu jāuzzina konkrētam veikalam precīzs fonta nosaukums, kas tiek izmantots čekos, tad jānopērk šī fonta oficiālā versija, un tikai uz tās bāzes jāapmāca valodas modelis atpazīt informāciju. Protams, šī ideālā versija prasītu tik daudz laika un naudas, ko students vienkārši nevar atļauties. Viktors piemeklēja tīmeklī pēc iespējas līdzīgākus fontus, kuri bija pieejami bez maksas, un izmantoja sava darbā tos. Jāpiebilst, ka sistēmu vajag apmācīt atpazīt burtus un ciparus ar dažādu veidu kropļojumiem, jo, piemēram, lietotājs katru reizi fotografēs čeku no nedaudz cita leņķa. Ja zinām, ka sākuma fonts jau nesakrīt par 100%, tad turpmākais rezultāts vēl attālinās no tiem 100%.
Visu, ko izdevās atpazīt no čeka, sistēma atspoguļo web-inerfeisā. Lietotājs var izlabot kļūdas, ja tādas ir bijušas. Izmantojot pieejamos datus, sistēma izveido un rada lietotājam divus grafikus: 1. kopējo tēriņu summu katrā mēnesī tekošajā gadā, 2. uz kādām preču vai pakalpojumu kategorijām procentuāli cik bija iztērēts (sk. attēlu).
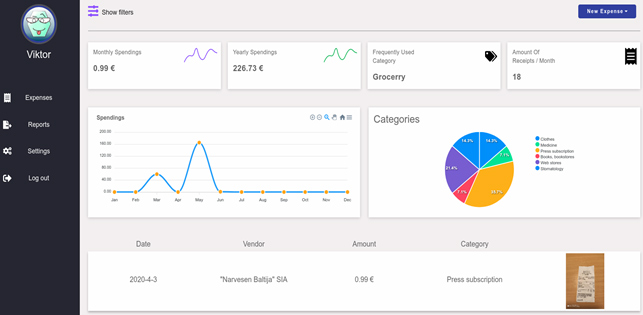
Vajadzēja sistēmai iemācīt labāk lasīt latviski
Viens no grūtākajiem uzdevumiem šajā projektā bija uzlabot valodas modeli tieši latviešu valodai, lai sistēma varētu veiksmīgi strādāt ar čekiem no Latvijas uzņēmumiem. OCR-bibliotēka “Tesseract”, kuru izmantoja Viktors, ir piemērota visām valodām, bet ne vienlīdz labi. Tas, cik labi strādā atpazīšana konkrētai valodai, ir atkarīgs no laika un datu apjoma (tekstu piemēru), kas kopumā tiek veltīts šīs valodas modeļa apmācībai. Līdere, protams, ir angļu valoda, jo tieši šī modeļa trenēšanai pievēršas visvairāk cilvēku pasaulē. Sava darba rezultātu uzlabošanai Viktoram nācās ieguldīt daudz laika un pūļu, lai vairāk uzlabotu latviešu valodas modeli.
Teorētiski pastāv valodas modeļa apmācības manuālais variants, kad tas tiek apmācīts tieši uz to datu pamata, ar kuriem sistēma strādās. Šajā gadījumā vajadzētu nofotografēt ļoti daudz kases čeku un pēc tam bildēs “iezīmēt” katru simbolu, lai dators saprastu, ka tieši šis ir burts “a” un šis – “z”. Var tikai iedomāties, cik gadu Viktoram vienam pašam vajadzētu veltīt tikai šim uzdevumam. Par laimi, atklāj Viktors, šo darbu var automatizēt ar skripta palīdzību: “Es paņemu vairākus fontus, automātiski izveidoju lielu daudzumu PDF-failu ar tekstiem šajā burtu rakstā, un uzdevu bibliotēkai tos atpazīt. Bija daudz jāeksperimentē, lai uzlabotu atpazīšanas radītājus”. Interesanti, ka šie teksti cilvēkam izskatās kā tīra bezjēdzība, jo sastāv no pangrammām – katrā teikumā ir izmantoti visi alfabēta burti. Vienlaicīgi skripts ģenerē arī teksta kropļojumus, lai pietuvinātu mākslīgi izveidotus datus reālajiem. Vienam fontam kļūdas procents sākotnēji bija 75%, pēc apmācības kļuva 40%. Tas, protams, joprojām ir daudz, bet darbs norisinājās pareizā virzienā. “Viss ir atkarīgs no uzdevumam veltītā laika. Manam datoram, ar esošo jaudu, vēl pamatīgāka modeļa trenēšana prasītu vairākas diennaktis nepārtraukta darba. Man nebija tādas iespējas. Izdarīju to, kas bija iespējams, un rezultāts jūtami uzlabojās”, atzīst Viktors.
Te var redzēt, kā samazinājās kļūdas procents pēc valodas modeļa apmācības uz atsevišķiem fontiem:
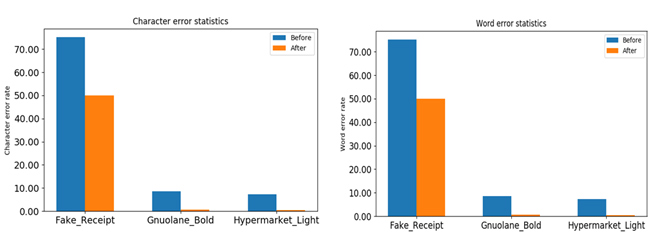
Kopā latviešu valodas modeļa trenēšanai Viktors izmantoja 7 fontus, katram izveidojot 500 lapas ar tekstu, un veltīja šim uzdevumam vairāk kā 24 stundas.
Darbs ar apmācītu modeli arī prasīja radošu pieeju, turpina pētnieks: “Vienā brīdī mans trenētais modelis deva sliktākus rezultātus nekā sākotnējais. Tikt galā ar šo problēmu nebija viegli. Teksta atpazīšana apvieno trīs jomas: datorredzi, mašīnmācīšanos un dabiskās valodas apstrādi. Diemžēl, ir ļoti ierobežots resursu – grāmatu, videostundu utt. – skaits par šo tēmu, tāpēc daudz ko nācās risināt eksperimentu ceļā. Beigās es secināju, ka var apvienot angļu un latviešu valodas modeļus, jo daudzi burti sakrīt, un tad rezultāti uzlabojās”.
Arī citus sistēmas elementus Viktors apguva pašizglītības ceļā. Piemēram, speciālas programmēšanas valodas un tehnoloģijas krosplatformu aplikācijas izveidei (lai tā strādātu gan iOS, gan Android ierīcēs), kā arī datorredzes algoritmus.
Ir iespējas uzlabojumiem
Jautāsiet, kur tad var lejuplādēt un izmēģināt šo sistēmu? Pagaidām nekur. Viktors apsvēra iespēju uz bakalaura darba aizstāvēšanas brīdi publicēt aplikāciju lielākajos veikalos, bet atteicās no šīs idejas: “Aplikācijas darba kvalitāte joprojām nav pietiekoši augsta. Lietotāji, savukārt, diezgan skarbi vērtē produktus, kuri nestrādā uz 100% labi. Tehniski neizglītotam cilvēkam ir grūti saprast, cik sarežģīti ir atpazīt tekstu, it īpaši ja tam ir slikta kvalitāte. Nolēmu, ka man tas nav vajadzīgs – lasīt negatīvas atsauksmes un rupjus komentārus. Speršu šo soli, kad vismaz 90% gadījumu teksts tiks atpazīts pareizi, kā arī izdosies uzlabot sistēmas darba ātrumu”.
Ir skaidrs, ka, ieguldot vairāk laika un naudas, esošo sistēmas versiju var ievērojami uzlabot. Autors netaisās pie tā apstāties un plāno automatizēt valodas modeļu apmācības sistēmu un beigās pievienot sistēmai visas iespējamās valodas. Viņam ir arī ideja, kā izmainīt tēriņu kategorijas noteikšanas mehānismu, lai tas nebūtu “piesiets” pie Latvijas tirgus un vietnes 1188.lv. Vajadzētu izmantot dabiskās valodas apstrādes tehnoloģiju, kas ļaus noteikt kategoriju pēc atslēgas vārdiem, kuri atrodami konkrētajā čekā. “Pastāv globāli apmācīts modelis, kurš ir trenēts uz miljoniem teksta rindu, un pēc atslēgas vārdiem diezgan labi nosaka kategoriju. Atkal, tas attiecas uz angļu valodu. Latviešu un citu valodu atpazīšanai būs vajadzīgs papildu darbs”.
Viktors pastāvīgi strādā pie sistēmas uzlabošanas: “Man izdevās paātrināt darbu. Iepriekš katra čeka apstrādei vajadzēja apmēram 20 sekundes. Protams, man ir parasts dators, kurš nav īpaši jaudīgs, un no tā arī ir atkarīgs ātrums. Tomēr pat pie esošas jaudas es panācu, ka viens čeks tagad tiek apstrādāts 10-12 sekunžu laikā – divreiz ātrāk”. Viņš turpina pētīt pieejamos avotus, lai izdomātu jaunus veidus sistēmas pilnveidei.
“Manis izveidotā aplikācija ir universāla tādā ziņā, ka tās elementus var izmantot ļoti dažādos projektos, kur ir vajadzība pēc teksta atpazīšanas. Man personiski pats vērtīgākais ir pieredze, kuru saņēmu, veidojot sistēmu”, secina TSI absolvents. Pēc augstskolas absolvēšanas, pateicoties šī projekta panākumiem, Viktoram izdevās saņemt darbu, kas ir tieši saistīts ar viņa iemīļoto tēmu. Viņš šobrīd strādā projektā, kurā veic personas apliecinošo dokumentu – ID-karšu, pasu, vadītāja apliecību – automātisku atpazīšanu. Pateicoties Viktora un viņa kolēģu darbam dators var pārbaudīt, vai dokumentam nav beidzies derīguma termiņš; vai dati, kuri ir norādīti rakstiski, sakrīt ar datiem, kuri ir iekodēti dokumenta tā sauktajā mašīnlasāmajā zonā; vai cilvēka fotogrāfija ir īsta, nav izmanīta grafiskajā redaktorā.
